L’explicabilité des modèles au cœur des enjeux IA à la SNCF
Face à l'utilisation croissante de l'intelligence artificielle dans l'aide à la prise de décision, l'explicabilité est devenue une brique essentielle et indispensable dans le cycle de vie des projets d'IA pour améliorer la compréhension du processus décisionnel des modèles et encourager l’utilisation de ses prédictions.
Publié le 31 janvier 2022 par Com itnovem

De la conception jusqu’à l’industrialisation de solutions Big Data et/ou d’Intelligence Artificielle, les projets de la Data/IA Factory reposent sur des techniques d’apprentissage automatique alimentées par des modèles de plus en plus complexes pour répondre à des enjeux à forts impacts, comme la prédiction des retards des trains Transilien ou la prédiction des risques de pannes sur les wagons. La réussite de ces projets repose à la fois sur la performance du modèle mais également de la capacité à pouvoir interpréter.
Cet équilibre entre performance et explicabilité n’est pas toujours facile à trouver. En général, les modèles très performants sont souvent complexes et donc peu interprétables. En conséquence, il est nécessaire voire crucial de faire appel à des méthodes d’explicabilité pour d’une part permettre aux Data Scientists d’améliorer leur modèle et d’autre part, encourager les métiers à utiliser l’IA pour palier leurs problématiques. Retrouvez la parole d’expert de Soumaya Ihihi et de Sohaibe Mohammad, Data scientist à la Factory Data IA d’ITNOVEM.
Partie 1
Lors de la conception du modèle par le Data Scientist, la compréhension de l’origine de ses biais permet de les corriger pour atteindre de meilleures performances et améliorer la robustesse du modèle. La compréhension du processus décisionnel du modèle permet aussi une meilleure adoption par les métiers qui s’appuient sur ses prédictions.
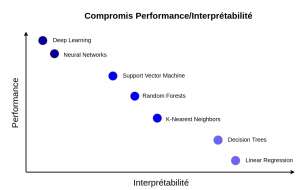
Figure 1 : C ompromis entre la performance et l’interprétabilité d’un modèle d’apprentissage automatique. Les modèles comme les réseaux de neurones peuvent être très performants mais peu interprétable, contrairement à d’autres modèles comme la régression linéaire qui est facilement interprétable mais peu performante pour modéliser des phénomènes complexes.
Les niveaux d’explicabilité (Local vs Global)
L’explicabilité d’un modèle d’apprentissage automatique peut se faire à deux niveaux (globalement ou localement). Le premier niveau, “l’explicabilité globale”, consiste à comprendre le comportement général du modèle. Plusieurs techniques permettent d’interpréter globalement un modèle, en fournissant des informations sur l’importance et l’impact des variables sur le modèle, et sont décrites dans l’article suivant.
Dans la suite, nous nous intéresserons au deuxième niveau, “l’explicabilité locale”, qui permet d’améliorer la compréhension de chaque décision du modèle de manière indépendante.
L’ensemble des techniques abordées dans cette série d’articles ont été intégrées à une librairie interne “readML” qui a pour objectif de centraliser les techniques d’explicabilité les plus pertinentes et faciliter leur utilisation.
Cas d’usage
Afin d’illustrer les différentes méthodes présentées dans cette série d’articles , nous nous appuierons sur un des projets réalisés à la Factory Data IA. Son objectif est d’anticiper les risques de pannes sur les wagons qui ne sont pas équipés de capteurs, pour pouvoir ensuite déclencher des opérations de maintenance spécifiques sur les wagons à risque, afin d’éviter la panne en ligne.
Pour répondre à cette problématique, nous avons entrainé un modèle à prédire la présence ou l’absence de panne des wagons, en fournissant un degré de fiabilité de la prédiction, en fonction de plusieurs variables comme l’âge du wagon, le nombre de kilomètres parcourus depuis la dernière intervention, le nombre de jours écoulés depuis la dernière intervention etc.
Pour ce projet, l’explicabilité des résultats du modèle est indispensable car ses prédictions ont un impact direct sur l’utilisateur final (l’opérationnel) qui doit décider de la pertinence de planifier une opération de maintenance en fonction de la prédiction du modèle. Une panne non détectée risque d’impacter la régularité des trains et inversement planifier une opération de maintenance inutile engendre des coûts en plus.
Il est donc indispensable de fournir des éléments supplémentaires sur les raisons des prises de décisions du modèle.
Explicabilité locale – Expliquer une prédiction avec SHAP
Plusieurs techniques d’explicabilité locale sont apparues récemment comme LIME ou DeepLIFT, mais la méthode retenue pour expliquer les prédictions de panne est SHAP.
SHAP (SHapley Additive exPlanation) par Lundberg & Lee (2016) est une approche issue de la théorie des jeux coopératifs qui permet d’expliquer la sortie de n’importe quel modèle d’apprentissage automatique. Une librairie qui porte le même nom est disponible en open source et propose plusieurs méthodes d’interprétabilité qui dérivent d’autres techniques (comme LIME, DeepLIFT, etc.).
Le but de SHAP est d’expliquer la prédiction d’une observation X (représentée par un ensemble de variables Xi), en calculant la contribution de chaque variable Xi à la prédiction Y en s’appuyant sur les valeurs Shapley.
Shapley values
Les valeurs Shapley, nommées en honneur à Lloyd Shapley, sont la réponse à une problématique issue de la théorie des jeux coopératifs, qui consiste à trouver la répartition la plus équitable des gains aux joueurs en fonction de la contribution de chaque joueur et en respectant les contraintes :
- Additivité : la somme des valeurs Shapley correspond au montant/gain final
- Cohérence : plus la contribution est élevée plus le sera la récompense/prix
Par analogie, SHAP considère que les valeurs des variables d’une observation représentent des joueurs dans un jeu coopératif où le gain est la prédiction du modèle pour cette observation. Les valeurs de Shapley nous indiquent comment répartir équitablement le “gain” (= la prédiction) entre les variables.
La librairie SHAP propose plusieurs méthodes pour calculer les valeurs Shapley, appelées “explainers”. Ces méthodes peuvent être agnostiques (indépendantes du type de modèle) comme Kernel SHAP ou spécifiques (à un certain type de modèle) comme Tree SHAP et Deep SHAP.
Le modèle utilisé pour prédire les pannes des wagons étant un LightGBM, nous allons utiliser la méthode Tree SHAP qui est une méthode spécifique pour les modèles de ML basés sur des arbres de décision (tels que les Random Forest, XGBoost, LightGBM …).
Ainsi, SHAP permet d’interpréter localement la sortie d’un modèle, et fournit une mesure de la contribution de chaque variable à la prédiction.
![]()
![]()
Figure 2 : Interprétation de l’impact des variables pour deux exemples d’observations. En rouge, les variables qui ont un impact positif (contribuent à augmenter la prédiction) et en bleu, celles ayant un impact négatif (contribuent à diminuer la prédiction). La valeur de base correspond à la probabilité de panne moyenne prédite par le modèle sur tout le jeu de donnée (0,1074).
Pour le premier exemple ci-dessus, le modèle a prédit une probabilité de panne de 0,05 (valeur en gras). Les variables qui ont le plus contribué à diminuer cette probabilité sont les “code_cr” (code répartition) et “code_cs” (code statistique), contrairement à la variable “days_since_last_interv” qui a un impact positif sur cette probabilité mais faible comparé à ces deux variables.
Ces interprétations permettent d’améliorer la compréhension des décisions du modèle. En fournissant des interprétations à l’utilisateur final, il peut vérifier la cohérence de la prédiction du modèle et décider de la pertinence de planifier une intervention pour réparer le wagon.
Conclusion
Face à l’utilisation croissante de l’intelligence artificielle dans l’aide à la prise de décision, l’explicabilité est devenue une brique essentielle et indispensable dans le cycle de vie des projets d’IA pour améliorer la compréhension du processus décisionnel des modèles et encourager l’utilisation de ses prédictions.
L’explicabilité peut aussi permettre de mettre en évidence les variables sur lesquelles on peut agir pour éviter la panne par exemple et donc les actions pertinentes à lancer.
Dans cet article, nous avons introduit l’importance de l’interprétabilité et présenter la librairie SHAP qui permet d’expliquer chaque décision ou prédiction d’un modèle de Machine Learning de manière indépendante. Les modèles basés sur des réseaux de neurones profonds nécessitent de faire appel à d’autres méthodes d’explicabilité qui feront l’objet d’un autre article.
Dans l’article suivant, nous nous focaliserons plus sur l’interprétabilité globale des modèles qui a pour objectif de démystifier le comportement général du modèle sur les données d’entraînement.
Partie 2
L’intelligence artificielle a permis de répondre à des problématiques complexes en apprenant directement des données. Néanmoins, ces modèles d’apprentissage soulèvent de nombreuses questions quant à leur explicabilité ce qui engendre des fois un rejet de la part des métiers ou des clients les utilisant. Pour encourager l’adoption des outils d’IA, il est donc essentiel de proposer une approche permettant d’améliorer la compréhension du processus décisionnel des modèles.
Dans l’article précédent, nous avions abordé l’importance de l’explicabilité dans le cycle de vie des projets d’IA en se focalisant sur le niveau le plus fin de l’explicabilité à savoir l’interprétabilité locale, qui permet d’expliquer chaque décision du modèle d’apprentissage automatique de manière indépendante.
Dans cet article, nous nous intéresserons à l’explicabilité globale à travers 4 techniques qui permettent d’expliquer le comportement global du modèle sur les données d’entraînement en fournissant des informations sur l’importance et l’impact des variables sur le modèle.
Explicabilité globale
Comme évoqué dans l’article précédent, l’explicabilité globale consiste à comprendre le comportement général du modèle. Cette étape est indispensable pour valider l‘entraînement du modèle à travers la vérification de la cohérence de l’importance accordée par le modèle aux variables avec la connaissance métier du domaine. Cette vérification permettrait par la suite d’améliorer la robustesse du modèle pour atteindre de meilleures performances.
Pour interpréter globalement un modèle, il est nécessaire de connaître d’un côté, l’importance globale des variables, en mesurant les contributions de toutes les variables à l’entraînement du modèle grâce aux valeurs SHAP, et de l’autre côté l’effet de variation de chaque variable sur la sortie des modèles à travers les tracés PDP (Partial Dependency Plot), ICE (Individual Conditional Expectation) et ALE (Accumulated Local Effects).
Pour illustrer ces 4 techniques d’explicabilité globale, agnostiques au modèle, nous nous appuierons sur le même exemple de projet présenté dans l’article précédent. Ce projet consiste à entraîner un modèle de classification binaire à prédire les pannes des wagons à partir de plusieurs variables comme l’âge du wagon, le nombre de kilomètres parcourus depuis la dernière intervention, le nombre de jours écoulés depuis la dernière intervention etc.
A- Importance globale des variables – SHAP
Dans l’article précédent, nous avons utilisé SHAP, une approche issue de la théorie des jeux coopératifs, pour interpréter localement les résultats du modèle de prédiction des pannes des wagons.
En plus d’interpréter localement chaque prédiction du modèle, SHAP permet aussi de comprendre le fonctionnement global du modèle en fournissant des informations sur l‘importance globale des variables et leurs impacts en fonction des valeurs de chaque variable.
Pour interpréter globalement un modèle, SHAP calcule la contribution de chaque variable à la prédiction finale pour toutes les observations du jeu d’entraînement.
En moyennant les valeurs absolues des valeurs de SHAP pour chaque variable, nous pouvons visualiser l’importance globale des variables, comme le montre la figure ci-dessous :
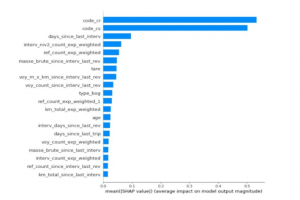
Figure 1 : Importance globale des variables. Les 20 variables les plus importantes sont ordonnées par importance. Le modèle accorde plus d’importance à la variable “days_since_last_interv” comparé à l’“âge” du wagon.
On peut également exploiter les valeurs SHAP calculées pour chaque observation du jeu d’entraînement afin d’analyser l’impact des variables en fonction de leurs valeurs.
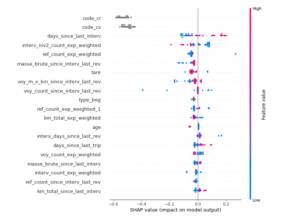
Figure 2 : Importance globale des variables et leur impact en fonction des valeurs de chaque variable (en rouge les valeurs élevées de la variable et en bleu les valeurs basses). Les variables sont ordonnées par importance et les valeurs de SHAP sont représentées pour chaque variable sur l’axe horizontal.
Sur ce graphe, en plus de l’importance globale des variables, nous pouvons voir que quand la variable “days_since_last_interv” prend des valeurs élevées (points rouges), cela a un impact positif sur la probabilité d’avoir une panne (valeur SHAP positive sur l’axe horizontal) et inversement quand cette variable prend des valeurs faibles (points bleus), la probabilité de panne diminue.
B – Impact de la variation d’une variable sur le modèle
Grâce au calcul des contributions des variables avec SHAP, nous avons une meilleure visibilité sur l’importance globale accordée par le modèle aux variables pendant l’entraînement. En plus de cette information, il serait intéressant de quantifier l’impact de la variation de chaque variable sur le modèle.
Nous avons retenu 3 techniques permettant de mesurer l’impact de la variation d’une (ou deux) variable(s) sur n’importe quel modèle : les tracés PDP, ICE et ALE.
Pour illustrer le fonctionnement des 3 méthodes, nous nous intéresserons particulièrement à la variable “days_since_last_interv” qui représente le nombre de jours écoulés depuis la dernière intervention sur le wagon.
1 – PDP (Partial Dependency Plot) et ICE (Individual Conditional Expectation)
Les tracés PDP et ICE ont pour objectif de quantifier l’effet marginal d’une (ou deux) variable(s) sur les prédictions d’un modèle d’apprentissage automatique.
Le processus permettant d’inspecter l’effet de la variation d’une variable sur le modèle avec la méthode ICE est le suivant :
- Pour une observation donnée, on fait varier la valeur de cette variable de manière à ce qu’elle prenne toutes les valeurs présentes dans le dataset.
- Pour chacune de ces valeurs, on récupère la prédiction associée
- On réitère ce processus pour chaque observation de la donnée
- On trace les courbes ICE (une courbe étant associée à une observation)
Le tracé PDP est simplement la moyenne des courbes ICE pour chaque valeur prise par la variable.
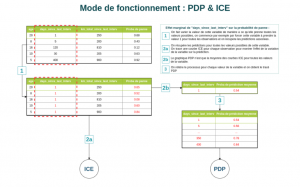
Figure 3 : Mode de fonctionnement des méthodes PDP et ICE sur la variable “days_since_last_interv”.
Pour simplifier, nous ne considérons que 3 variables pour prédire les pannes des wagons et nous nous intéressons à l’effet de la variation de la variable “days_since_last_interv” sur la probabilité de panne.

Figure 4 : Tracé PDP (gauche) et ICE (droite) de la variable “days_since_last_interv”. D’après les tracés PDP et ICE (orange), le risque de panne augmente en fonction du temps écoulé depuis la dernière intervention jusqu’à un seuil (250 jours). Pour simplifier le tracé PDP, les valeurs de la variable ont été découpées en 10 intervalles.
Ces deux méthodes ont une implémentation assez intuitive et simple. Cependant, du fait de la moyenne réalisée, les courbes PDP risquent de masquer les effets hétérogènes entre les variables. C’est pourquoi, il est souvent conseillé d’utiliser les tracés PDP et ICE ensemble pour une meilleure interprétation.
2 – ALE (Accumulated Local Effects)
La méthode ALE est une alternative plus rapide et moins biaisée que les tracés PDP.
En effet, pour tracer les graphiques PDP et ICE, on a commencé par remplacer la variable “days_since_last_interv” par 0 pour toutes les observations, y compris l’observation pour laquelle la variable “km_total_since_last_interv” vaut 900 Km (ce qui est peu réaliste). L’effet de cette observation irréaliste a donc été pris en compte dans le calcul de l’effet de la variable.
Le graphique ALE dépasse cette limite en se reposant sur la distribution conditionnelle des variables et également en calculant des différences de prédiction au lieu des moyennes pour les PDP. Lorsqu’on veut comprendre l’effet associé à un nombre de jours qui varie entre 0 et 50, la méthode ALE utilise toutes les observations pour lesquelles cette variable est comprise entre 0 et 50 et calcule la différence en prédiction lorsque cette variable varie de 0 à 50.
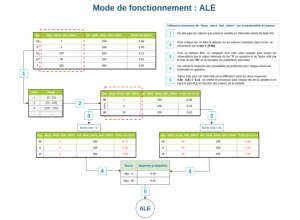
Figure 5 : Mode de fonctionnement de la méthode ALE.
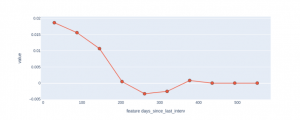
Figure 6 : Tracé ALE pour mesurer l’effet marginal de la variable ”days_since_last_interv” intervalle par intervalle.
La méthode ALE permet ainsi de quantifier l’impact de la variation de la variable sur la prédiction d’un modèle en limitant le biais lié à la corrélation des variables introduits (contrairement aux tracés PDP). Comme les variables sont souvent corrélées, il est souvent conseillé de privilégier la méthode ALE.
CONCLUSION
Il est important pour le métier mais également pour les Data Scientists de repérer les variables qui ont le plus d’impact sur la prise de décision du modèle. L’impact de certaines variables peut paraître intuitif mais il arrive que dans certains cas, des variables jugées moins importante ont une importance considérable sur les prédictions.
Dans cet article, nous avons parcouru plusieurs méthodes d’explicabilité permettant d’expliquer globalement l’importance des variables dans la prise de décision des prédictions du modèle. Nous avons ainsi exploré les méthodes PDP, ICE, ALE et SHAP qui ont chacune leur mode de fonctionnement mais aussi leurs limites.
L’ensemble de ces techniques ont été implémentées dans une librairie interne à la Factory Data IA de la SNCF. Cet article n’étant qu’une revue globale, nous vous recommandons vivement de lire “Interpretable Machine Learning” de Christoph Molnar pour plus de détails.