Maintenir des versions à jour : un élément essentiel du MCO applicatif
Un scénario classique : le projet est enfin terminé, et l'application est en bon état de marche. Pourtant, l'intervention régulière d'un développeur, quoique ponctuelle, est toujours nécessaire. Pourquoi ? Qu’est-ce qui se cache derrière le terme de "maintien" d'un logiciel, d'une librairie ? Qu’est-ce qui impose de revenir sur une application dont le bon fonctionnement a été validé ? Réponses avec notre expert Romain Gouron, Data Engineer chez ITNOVEM.
Publié le 16 janvier 2024 par Elodie

Introduisons quelques concepts :
- Le maintien en condition opérationnelles (MCO) est l’ensemble des opérations nécessaires à la garantie d’une application (ou SI, pour Système d’Information) en bon état de marche
- L’environnement d’exécution : un SI ne fonctionne pas « dans le vide ». De la même manière qu’une voiture roule sur la route, un SI doit s’exécuter dans un contexte :
- un système d’exploitation (ou OS, pour Operating System) pour un conteneur, un ordinateur personnel, une machine virtuelle (VM pour Virtual Machine), un serveur, etc.
- un runtime pour une plateforme managée (Databricks par exemple)
- Les dépendances (ou librairies, ou même « lib ») désignent l’ensemble du code préexistant et disponible sur lequel s’appuie le code de notre application. On peut dire que via ce code, notre application « sous-traite » une partie des fonctionnalités dont elle a besoin. Ces fonctionnalités peuvent être très diverses, comme des fonctions mathématiques, de gestion de date ou d’accès à une base de données.
Revenons un instant sur l’environnement d’exécution. Pour les OS, l’utilisateur est tributaire des versions qui lui sont proposées : Windows 8 n’est par exemple plus proposé aux nouveaux acquéreurs d’un PC depuis janvier 2023. Idem pour les runtimes de Databricks, l’utilisateur ne peut choisir que parmi une liste bien définie, qui évolue au cours du temps. Ceux qui continuent d’utiliser une version caduque ont été informés que leurs bugs ne seraient plus pris en charge. Autrement dit, au nom du MCO, ils ont été invités à effectuer… une migration.
1. La migration vers Spark 3, une impulsion de la plateforme Databricks
Spark est un outil de traitement de données utilisant le calcul distribué, très présent dans l’univers du big data. Il est très performant et permet de faire de nombreux traitements avec une rapidité de calcul inédite.
Prenons un scénario concret : notre application a été développée sur la base de cet outil. Il a été encensé à l’avant-vente et maintenant qu’il a été développé, puis mis en production, on annonce qu’il a besoin d’une mise à jour. Pourquoi ? Est-ce normal ? Habituel ? Et d’abord, en quoi consiste une mise à jour ? Et quelle différence avec une migration ?
1.1. Une apparente simplicité : un numéro à changer…
Les points d’attache d’un numéro de version sont la plupart du temps très peu nombreux : en Scala il est entièrement contenu dans le pom.xml (avec Maven), ou dans le requirements.txt en Python.

Figure 1 : Un champ à remplacer dans le pom.xml
Tout semble donc très simple. Cependant, les développeurs ont estimé la charge liée à la montée de version : le chef de projet annonce deux semaines de développement au client. S’est-il moqué de lui ?
1.2. …qui se répercute dans le code
Non, bien évidemment. Si l’acte de changer de version est immédiat, il a des répercussions qu’il faut gérer. Une nouvelle version, si elle est importante, ajoute de nouvelles fonctionnalités, en modifie certaines, en supprime d’autres. C’est d’ailleurs la nuance qu’on peut faire entre une montée de version, qui est synonyme de changements légers, et une migration, qui elle, implique de lourdes modifications. Parmi les changements dans le cas du passage de Spark 2 à 3, on peut citer, entre autres, les fonctions liées aux timestamps : celles-ci n’ont pas le même comportement face à un même format de données entre les deux versions. Observons ces différences, étant donné la commande suivante :
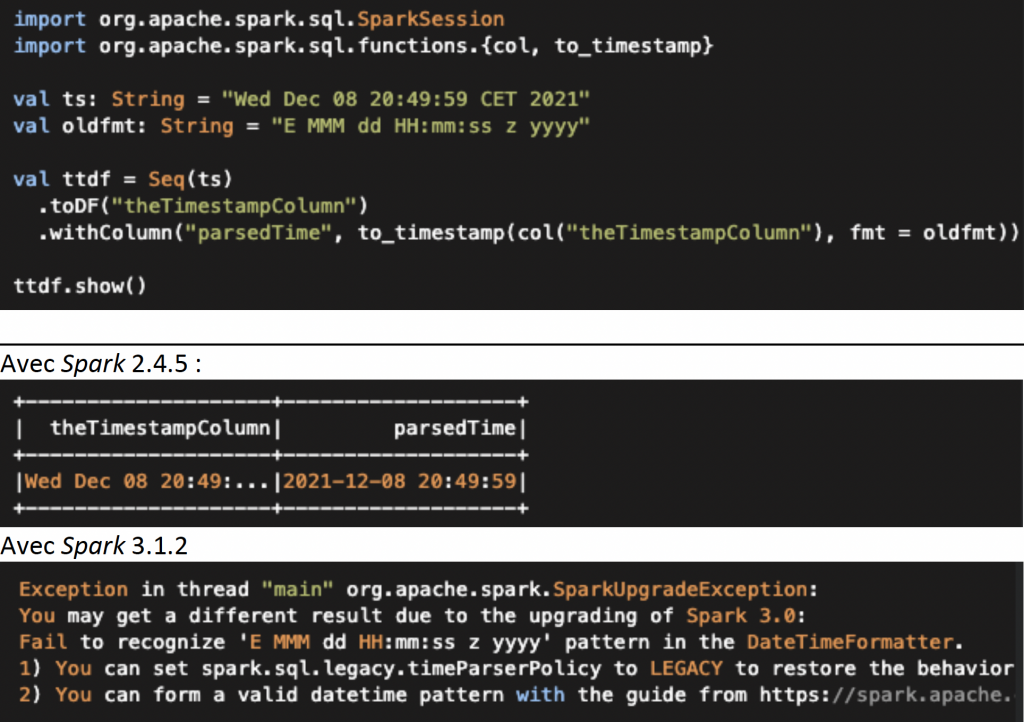
Figure 2 : le résultat de la commande selon les différentes versions
Le format de date est devenu invalide pour Spark 3, qui renvoie une exception. Il faut alors revoir les tests, qui ont peut-être été impactés par ces changements. Cet exemple illustre de façon concrète les évolutions dans le code qu’implique un changement de version, vu jusqu’alors comme une simple modification de valeur dans un fichier de config (pom.xml ou requirements.txt).
1.3. Les notions de support et la communauté : l’exemple d’iOS
En septembre 2010 sortait iOS 4, le système d’exploitation accompagnant l’iPhone 4. Compte tenu de la durée de vie des iPhones, il est légitime de supposer que plus personne n’utilise aujourd’hui cette version. Elle n’est d’ailleurs plus « supportée » par Apple, au sens où Apple n’assure plus de support utilisateur : les bugs rencontrés sur cette version ne sont plus pris en charge, et il n’y a plus de patches de sécurité proposés.
Le phénomène s’alimente lui-même : une chute d’utilisation pousse vers l’arrêt du support, qui lui-même entraîne une chute dans l’utilisation, etc. Mais penser qu’Apple est le seul contributeur aux fonctions de support serait une erreur. Comme on peut le constater sur les plateformes d’entraide comme StackOverflow, une grande partie de l’assistance est faite bénévolement par une communauté d’utilisateurs. L’argument précédent de l’obsolescence des logiciels s’applique également à celle-ci.
Figure 3 : Statistiques StackOverflow sur le tag « ios »
Une version à jour est donc une version supportée par l’éditeur, et soutenue par la communauté. Utiliser une version à jour, c’est maximiser les chances de réussite dans le processus de résolution d’une panne ou d’un bug.
Ces notions s’articulent autour du terme de LTS, ou long-term support. Il désigne certaines versions, choisies par l’éditeur, qui sont « faites pour durer », et qui garantissent à l’utilisateur qu’il n’aura pas à se préoccuper de la migration dans un futur proche. Par exemple, les runtimes LTS de Databricks sont supportés pendant 3 ans. C’est d’ailleurs la fin de vie d’une version LTS qui était à l’origine de la migration vers Spark 3 chez ITNOVEM.
Néanmoins, tous les changements de versions ne découlent pas directement de l’impulsion de l’éditeur : il est également possible qu’ils soient induits par un changement de version d’une autre dépendance de notre application. Voyons cela de plus près.
2. Le changement induit par transitivité
Considérons toujours notre application, qui utilise :
- Spark, qui dans notre exemple vient de passer de la version 2.4 à 3.4
- La librairie log4j en version 1.2.17 (noté ici log4j:1.2.17)
2.1. Changement mineur vs changement majeur, ou « breaking change »
Alors :
- On dit que Spark :3.4 et log4j :1.2.17 sont compatibles si elles peuvent fonctionner dans le même environnement.
- Spark 3.4 a été pensé pour fonctionner avec log4j:2.19.0. Si toutefois il pouvait s’utiliser avec log4j:1.2.17, ou avec des versions antérieures, on dirait que Spark 3.4 fait preuve de « backward compatibility », ou que la compatibilité est « maintenue ».

Figure 4 La Nintendo Wii (sortie en 2006) : un bon exemple de backward compatibility avec la GameCube (2001), dont onvoit ici un jeu et une manette
- Dans les faits, le changement de version de log4j correspond à la résolution d’une faille de sécurité. Spark 3.4 et log4j:1.2.17 ne sont plus compatibles, on dira que la montée de version entre Spark 2.4 et 3.4 présente des « breaking changes », qui justifient de « casser la compatibilité ».
C’est également le cas avec Scala : on ne peut plus dans Spark 3.0 utiliser la version 2.11, il faut migrer à la 2.12. Il est alors courant que l’éditeur propose des guidelines pour migrer d’une version à la suivante.
Pour synthétiser l’ensemble des versions compatibles entre elles, on peut utiliser une matrice de compatibilité. Ci-dessous, on en montre un exemple avec Spark et Scala :

Figure 5: Matrice de compatibilité de spark-code. Source : mvnrepository.com
Comme évoqué ci-dessus, Spark 2.3 n’est compatible qu’avec Scala 2.11, tandis que la Spark 3.5 est compatible avec Scala 2.12 et 2.13. En cas de migration de Spark 2.3 vers 3.5, il faudra donc également changer la version de Scala.
2.2. Le « dependency hell », ou le conflit de version généralisé
Définissons deux types de dépendances :
- Les dépendances directes, qui sont les composants auxquels un programme fait directement référence (par exemple Spark 3 pour notre application)
- Les dépendances transitives, qui sont les composants auxquels une dépendance fait référence, directement, ou par le biais d’autres dépendances. Une dépendance a donc elle-même des dépendances, qui chacune ont des dépendances, etc. : la liste croît comme les ramifications d’un arbre.
Gardons cela en tête et imaginons le scénario suivant :
On utilise Spark dans sa version 2.4.3, qui a deux dépendances : o log4J dans sa version 2.21 o SLF4J dans sa version 1.7.16. Or, SLF4J a également pour dépendance log4j, mais dans sa version 2.0.9. Pour les besoins de l’exemple, on suppose que les versions 1.7.16 et 2.0.9 sont incompatibles.
On résume les informations dans le schéma ci-dessous :
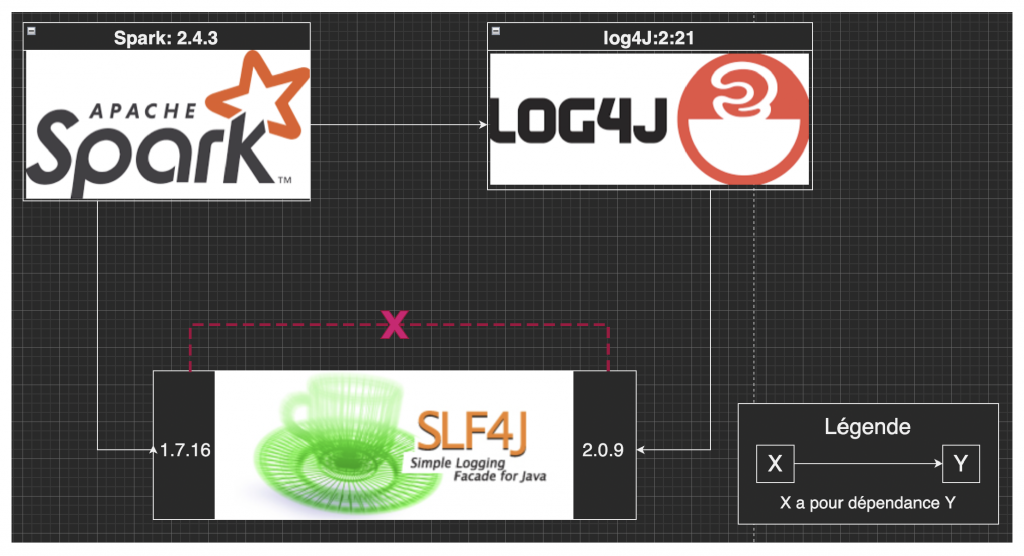
Figure 6 Schéma de dépendances entre Spark, log4j et SLF4J
Dans ce scénario, l’application ne pourra manifestement pas fonctionner. On comprend par ailleurs que ce plus les ramifications mentionnées ci-dessus sont longues, plus le scénario est susceptible de se produire. On désigne par « dependency hell » l’ensemble des complications (souvent jugées traumatisantes !) provoquées par ces mécanismes. Enfin, il existe un autre cas de migration forcée : celui de la faille de sécurité.
3. Le changement de version induit par la sécurité
3.1. « Une faille de sécurité a été découverte »
Que ce soit par des moyens analytiques de chercheurs en sécurité, par des hackers ou par de simples utilisateurs, il arrive qu’une librairie qu’on croyait sûre révèle une faille de sécurité exploitable. En général, ces failles sont rapidement corrigées : le danger réside dans l’intervalle entre la publication du correctif et sa mise à jour dans les applications concernées.
Mais également :
Supposons que notre application utilise une dépendance révélée comme vulnérable. Les développeurs sont vigilants et déploient rapidement la nouvelle version du correctif. En revanche, la dépendance JacksonXML, attend trois jours avant de changer de version – De plus, Jakarta XML, qui est une dépendance de JacksonXML attend, elle, une semaine… On comprend à travers ce mécanisme que la vulnérabilité peut perdurer tant que tous les maillons de la chaîne ne l’ont pas éliminée.
3.2. L’exemple de log4J
Apache log4j est une librairie utilisée par des millions d’applications Java. Le 9 décembre 2021, la vulnérabilité CVE-2021-44228 (pour « Common Vulnerabilities and Exposures »), puis re-baptisée Interne log4Shell est découverte. Celle-ci permet d’exécuter du code à distance sur les serveurs qui hébergent l’application utilisant log4j : la sévérité de la faille est maximale, 10 sur l’échelle CVSS. L’événement a un grand retentissement médiatique, car la vulnérabilité touche des services aussi importants qu’Apple (iCloud), Amazon, Twitter, Cloudflare, Steam, etc. Le gouvernement du Québec a d’ailleurs fermé 4000 de ses sites web à titre préventif, et afin d’éviter une exploitation de la faille.
3.3. Scan CVE : un outil grand public pour se prémunir de ces problèmes ?
Les failles du type log4Shell sont hors du commun et nécessite des moyens spéciaux. Pour les cas plus classiques, il est possible d’automatiser le passage en revue des dépendances pour savoir si elles sont sujettes à des vulnérabilités. Ce genre de programme pointe les versions des dépendances problématiques, évalue la criticité, et propose une version corrigée. Il est par exemple possible de configurer la pipeline d’intégration continue (CI) pour n’accepter un build que si aucune faille de sécurité n’est critique.

Figure 7: Un extrait de la sortie de l’outil de scan de CVE de JFrog
Conclusion
Nous avons passé en revue trois raisons qui poussent à changer la version d’un SI :
- Le changement lié à la fin de vie d’une version
- Le changement induit par transitivité
- Le changement induit par la sécurité
Celles-ci montrent que les migrations sont normales et font partie de la vie d’un SI. Maintenir à jour un SI est bénéfique, et il est moins coûteux de faire les opérations de maintenance régulièrement que d’attendre qu’elles s’accumulent pour les traiter en « batch ».